 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Clustering for Short Text via Deep Representation Learning
Jul 14, 2017
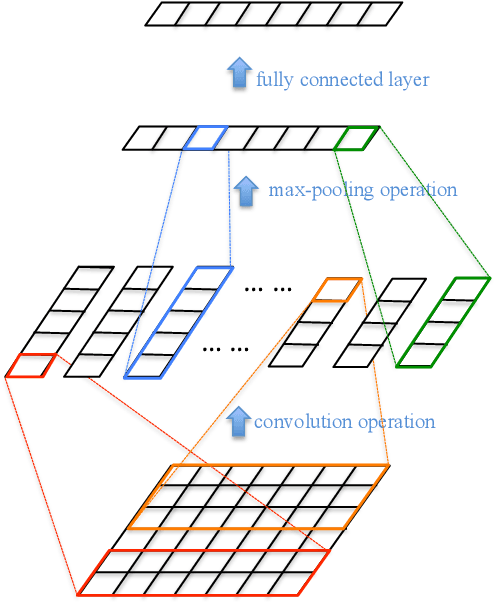
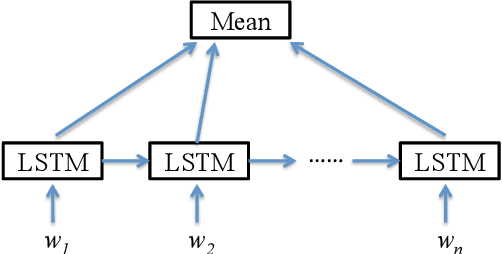

In this work, we propose a semi-supervised method for short text clustering, where we represent texts as distributed vectors with neural networks, and use a small amount of labeled data to specify our intention for clustering. We design a novel objective to combine the representation learning process and the k-means clustering process together, and optimize the objective with both labeled data and unlabeled data iteratively until convergence through three steps: (1) assign each short text to its nearest centroid based on its representation from the current neural networks; (2) re-estimate the cluster centroids based on cluster assignments from step (1); (3) update neural networks according to the objective by keeping centroids and cluster assignments fixed. Experimental results on four datasets show that our method works significantly better than several other text clustering methods.
Sentence Similarity Learning by Lexical Decomposition and Composition
Jul 14, 2017
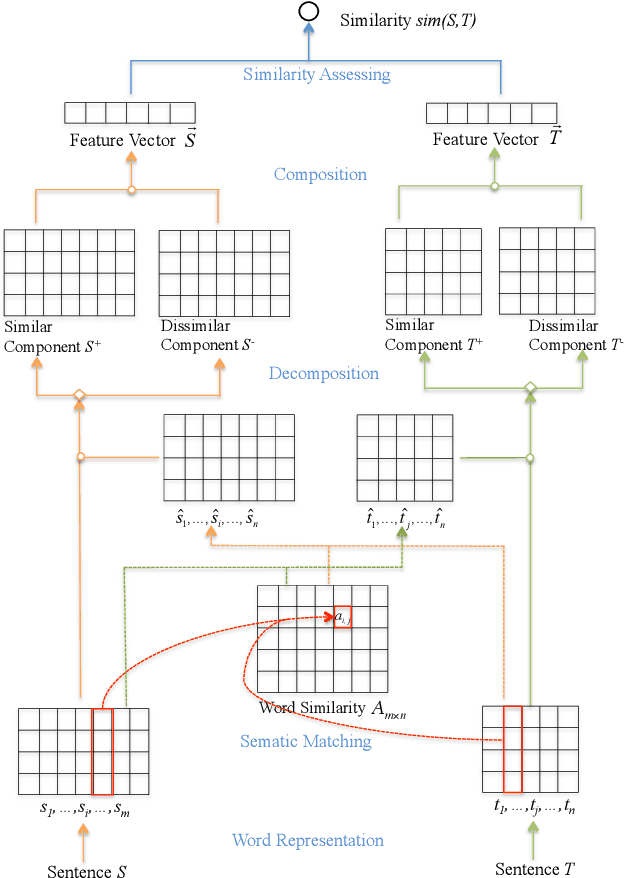
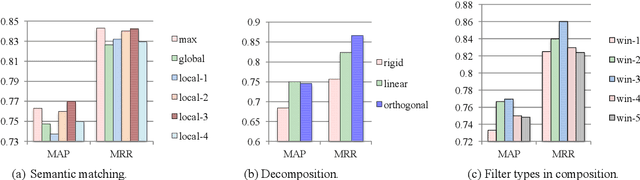
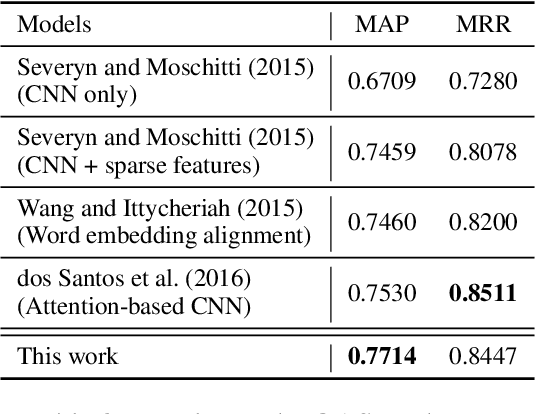
Most conventional sentence similarity methods only focus on similar parts of two input sentences, and simply ignore the dissimilar parts, which usually give us some clues and semantic meanings about the sentences. In this work, we propose a model to take into account both the similarities and dissimilarities by decomposing and composing lexical semantics over sentences. The model represents each word as a vector, and calculates a semantic matching vector for each word based on all words in the other sentence. Then, each word vector is decomposed into a similar component and a dissimilar component based on the semantic matching vector. After this, a two-channel CNN model is employed to capture features by composing the similar and dissimilar components. Finally, a similarity score is estimated over the composed feature vectors. Experimental results show that our model gets the state-of-the-art performance on the answer sentence selection task, and achieves a comparable result on the paraphrase identification task.
FAQ-based Question Answering via Word Alignment
Jul 09, 2015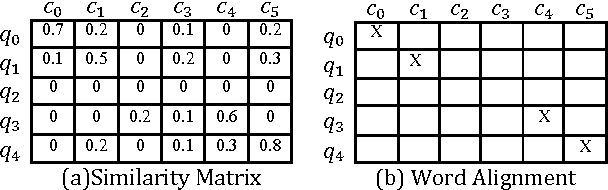
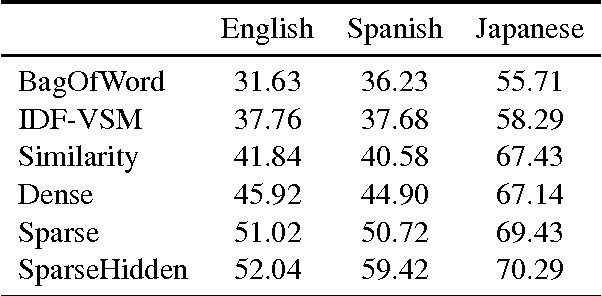
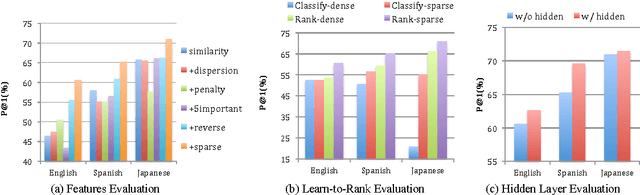
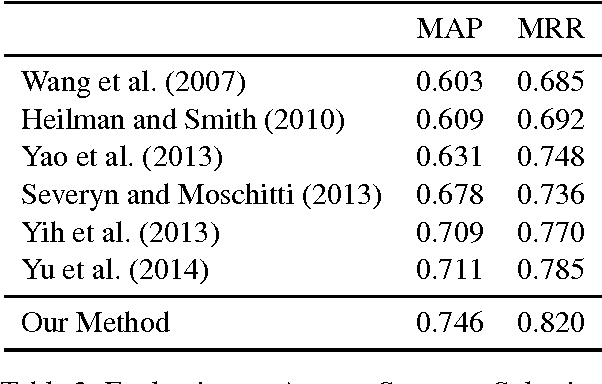
In this paper, we propose a novel word-alignment-based method to solve the FAQ-based question answering task. First, we employ a neural network model to calculate question similarity, where the word alignment between two questions is used for extracting features. Second, we design a bootstrap-based feature extraction method to extract a small set of effective lexical features. Third, we propose a learning-to-rank algorithm to train parameters more suitable for the ranking tasks. Experimental results, conducted on three languages (English, Spanish and Japanese), demonstrate that the question similarity model is more effective than baseline systems, the sparse features bring 5% improvements on top-1 accuracy, and the learning-to-rank algorithm works significantly better than the traditional method. We further evaluate our method on the answer sentence selection task. Our method outperforms all the previous systems on the standard TREC data set.